Provenance Data Model RFC #2 Page
History
IVOA Provenance DM has become a recommendation after validation by the DM WG , TCG board and Exec board. http://www.ivoa.net/documents/ProvenanceDM/20200411/index.html After the first RFC period (November 2018) during which no consensus was reached, the Provenance model has been revamped.- Based on a similar skeleton, this new version has significant differences with the former one.
- The current document has been issued after some intensive sessions held in the Spring-19 meeting in Paris
- After this, the TCG sugested to go in a new WG stage, shorten to 4 weeks, which actually ended on 2019/07/19.
Documents
The attached document presents the IVOA Provenance Data Model v1.0 which is proposed for review is accessible in ivoadoc. This document describes how provenance information can be modeled, stored and exchanged within the astronomical community in a standardized way. We follow the definition of provenance as proposed by the W3C (https://www.w3.org/TR/prov-overview/), i.e. that "provenance is information about entities, activities, and people involved in producing a piece of data or thing, which can be used to form assessments about its quality, reliability or trustworthiness."Such provenance information in astronomy is important to enable any scientist to trace back the origin of a dataset (e.g. an image, spectrum, catalog or single points in a spectral energy distribution diagram or a light curve), a document (e.g. an article, a technical note) or a device (e.g. a camera, a telescope), learn about the people and organizations involved in a project and assess the reliability, quality as well as the usefulness of the dataset, document or device for her own scientific work.
VODML: - The VO-DML XML file is accessible in ivoadoc/xml
- The VO-DML HTML documentation is accessible on Volute (for the record)
CTA implementations (M. Servillat)
The Cherenkov Telescope Array (CTA) is the next generation ground-based very high energy gamma-ray instrument. Contrary to previous Cherenkov experiments, it will serve as an open observatory providing data to a wide astrophysics community, with the requirement to propose self-described data products to users that may be unaware of the Cherenkov astronomy specificities. Because of the complexity in the detection process and in the data processing chain, provenance information of data products are necessary to the user to perform a correct scientific analysis. Provenance concepts are relevant for different aspects of CTA:- Pipeline: the CTA Observatory must ensure that data processing is traceable and reproducible, making the capture of provenance information necessary.
- Data diffusion: the diffused data products have to contain all the relevant context information as well as a description of the methods and algorithms used during the data processing.
- Instrument Configuration: the characteristics of the instrument at a given time have to be available and traceable (hardware changes, measurements of e.g. a reflectivity curve of a mirror, ...)
- a python Provenance class dedicated to the capture of provenance information of each CTA pipeline tool (including contextual information and connected to configuration information)
https://cta-observatory.github.io/ctapipe/api/ctapipe.core.Provenance.html - OPUS: a job controller that can execute predefined jobs on a work cluster and expose the results. This job controller follows the IVOA UWS pattern and the definition of jobs proposed in the IVAO Provenance DM (Description classes), so as to capture and expose the provenance information for each job and result via a ProvSAP interface.
https://opus-job-manager.readthedocs.io
Pollux Provenance: a simple access protocol to provenance of theoretical spectra (M. Sanguillon)
POLLUX is a stellar spectra database proposing access to high resolution synthetic spectra computed using the best available models of atmosphere (CMFGEN, ATLAS and MARCS), performant spectral synthesis codes (CMF_FLUX, SYNSPEC and TURBOSPECTRUM) and atomic line lists from VALD database and specific molecular line lists for cool stars. Currently the provenance information is given to the astronomer in the header of the spectra files (depending on the format: FITS, ASCII, XML, VOTable, ...) but in a non-normalized description format. The implementation of the provenance concepts in a standardized format allows users on one hand to benefit from tools to create, visualize and transform to another format the description of the provenance of these spectra and on a second hand to select data depending on provenance criteria. In this context, the ProvSAP protocol has been implemented to retrieve provenance information in different formats of the serialized data: PROV-N, PROV-JSON, PROV-XML, VOTABLE and to build diagrams in the following graphic formats: PDF, PNG, SVG. These serializations and graphics are generated using the voprov python package derived from the prov Python library (MIT license) developed by Trung Dong Huynh (University of Southampton).SVOM Quick Analysis (L. Michel)
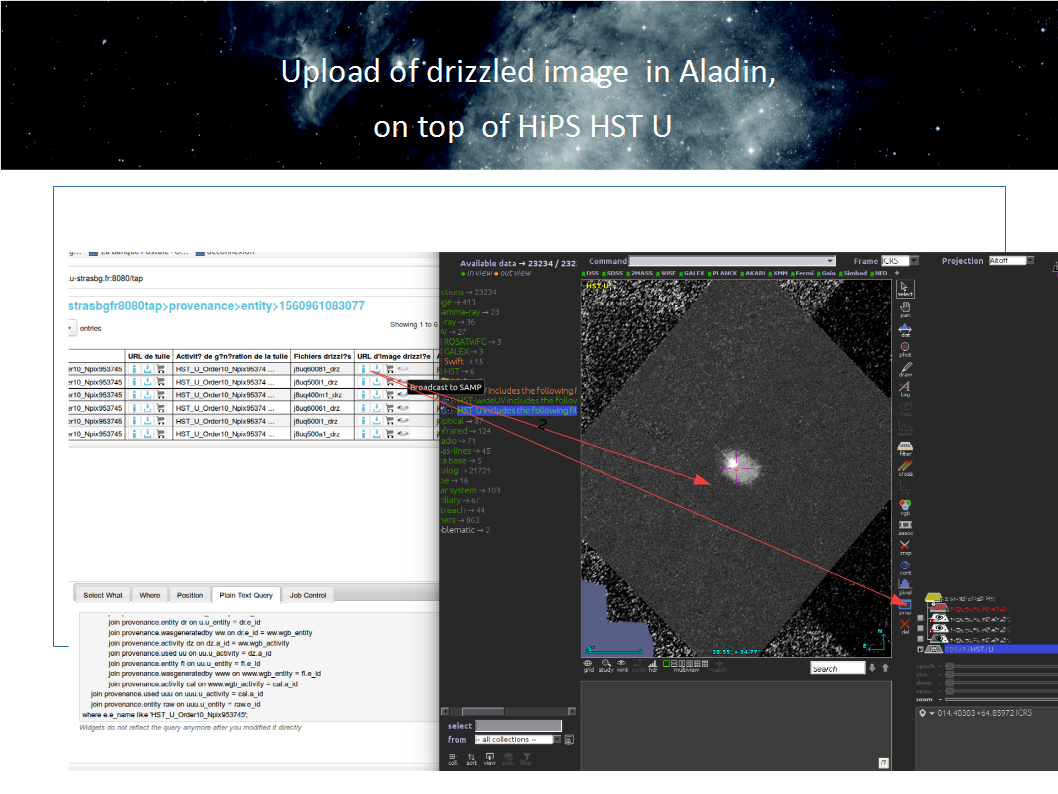
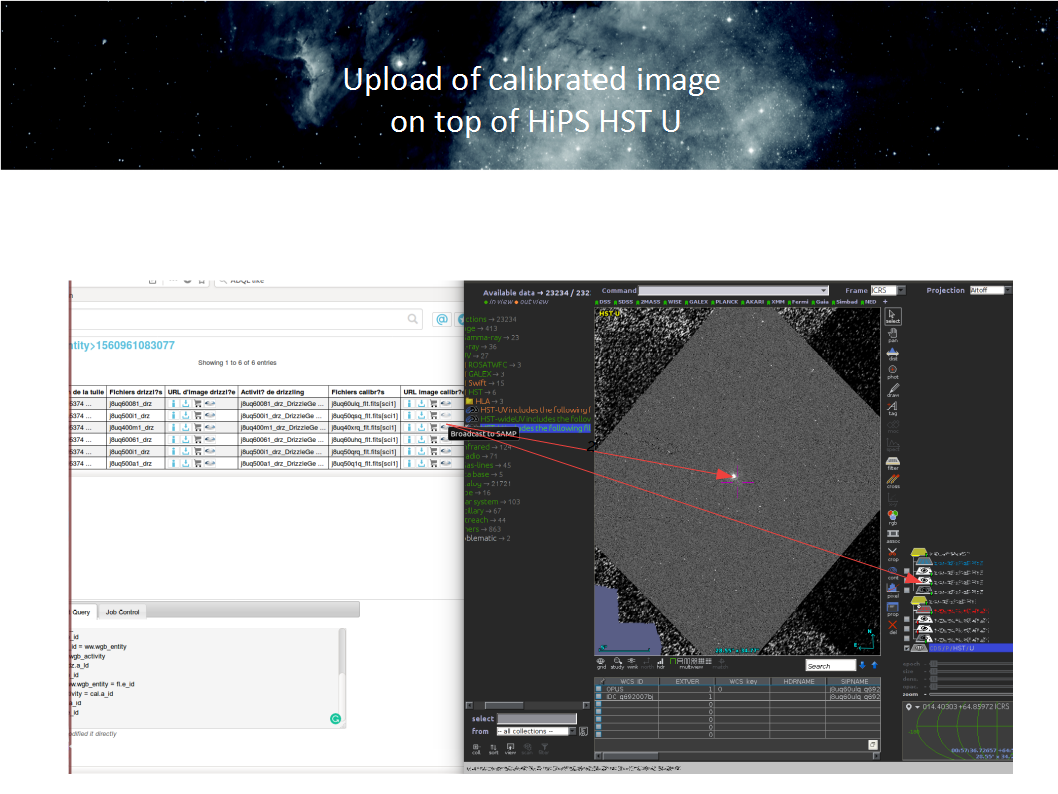
The SVOM satellite is a Sino-French variable object monitor to be launched in 2021. When a transient object is detected, a fast alert is sent to the ground station through a worldwide VHF network. Burst advocates and instrument scientists are in charge of evaluating the scientific relevance of the event. To complete the assement, scientists have at their disposal high level data products such as light curves or spectra generated by an automatic data reduction pipeline. In some case, they might need to reprocess raw data with refined parameters. To do so, scientific products (where calibration level satisfies calib_level >= 2) embed their JSON provenance serialization document in a specific file extension. This provenance instance can be extracted, updated and then uploaded as imput of a dedicated pipeline to reprocess the photon list with improved parameters.ProvHIPS CDS prototype service providing provenance metadata for HiPS datasets stored at CDS. ( F. Bonnarel, A. Egner)
This prototype is both an implementation of Provenance Data Model and of the DAL ProvTAP protocol. ProvTAP is a proposal for providing Provenance metadata via TAP services. The current draft for this DAL protocol definition (TBC) can be found here). It is basically providing a TAP-schema mapping the IVOA Provenance model onto a relational schema.- A first implementation of a TAP service for Provenance metadata bound to ObsTAP metadata was done by F . Bonnarel, M. Louys and G. Mantelet in August 2018.
- A second version of ProvHiPS was presented at ADASS (http://adass2018.astro.umd.edu/abstracts/O11-3.pdf) and was gathering provenance metadata on the process of transformation of original data collections into HiPS datasets.
A triple Store implementation for an image database (M.Louys, F.X Pineau, L.Holzmann, F.Bonnarel).
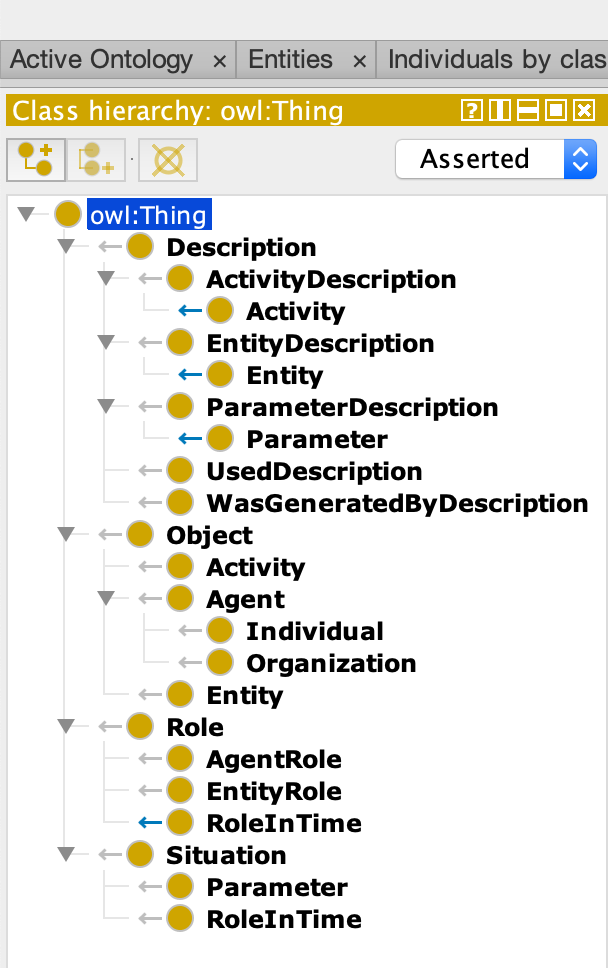
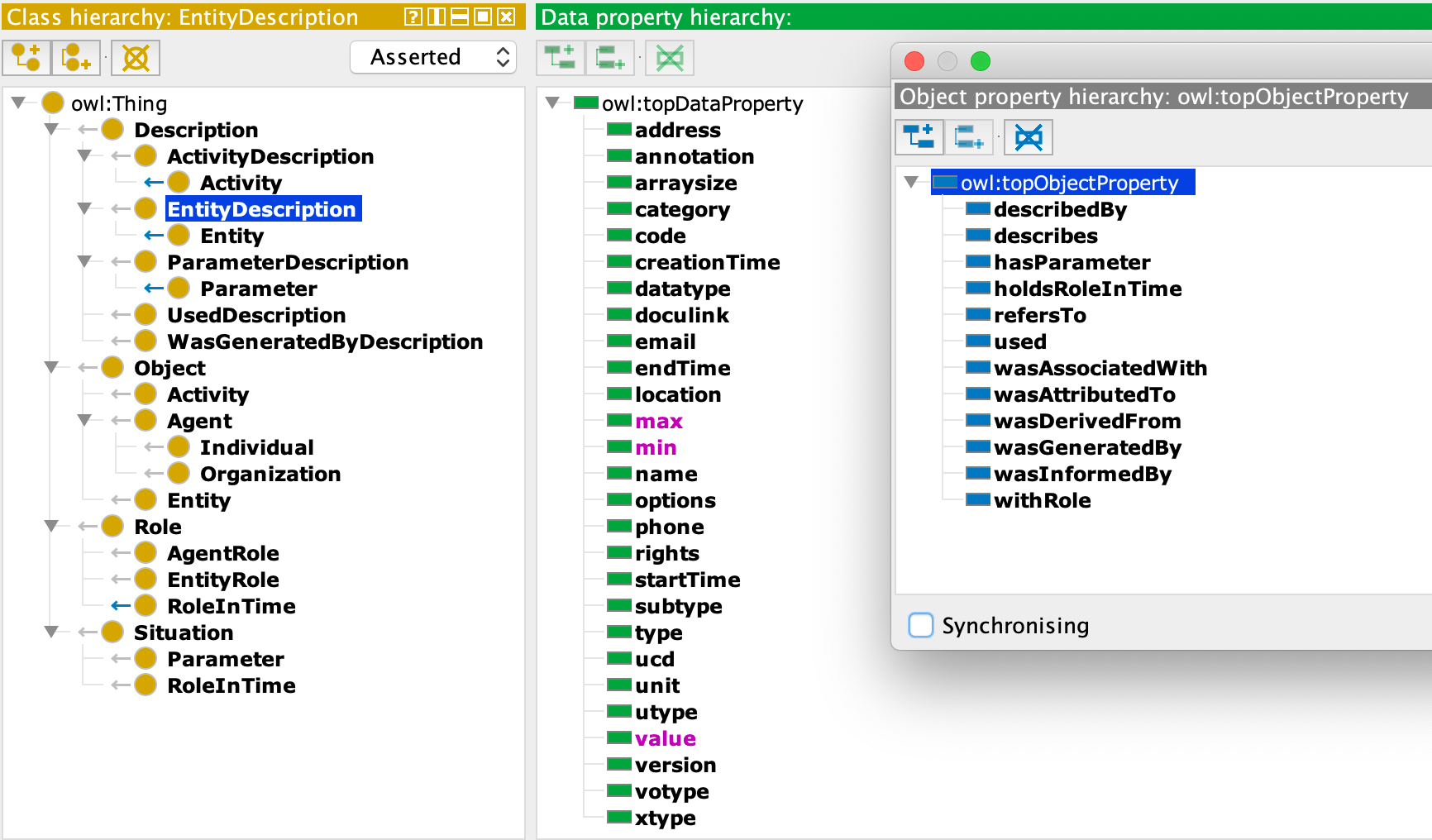
We have implemented the IVOA provenance DM proposed using a BlazeGraph triplestore data base. It handles astronomical images as Entities with a succession of Activities that produce or consume them. Entities represent image files or photometric plates. Activities are described by an ActivityDescription instance which gives the template for execution of several different Activity instances based on the same template. / The Blazegraph prov-test prototype translates the classes via an Ontology of Object in OWL. The Prov_Owl diagram attached exposes the main objects of this ontology. This prototype implements:- Agent, Activity, Entity ( mainly DatasetEntity)
- Used, wasGeneratedBy
- wasAssociatedTo, wasAttributedTo
- wasDerivedFrom
- hasParameter --> wasConfiguredBy
- ActivityDescription
- describedBy
- describes
- useddescription -->!UsageDescription
- wasgeneratedByDescription-->!GenerationDescription
- ParameterDescription
- Parameter
MuseWise Provenance: Implementation of ProvTAP, ProvSAP, W3C, and visualisation (O. Streicher)
MUSE is an integral field spectrograph installed at the Very Large Telescope (VLT) of the European Southern Observatory (ESO). It consists of 24 spectrographs, providing a 1x1arcmin FOV (7.5" in Narrow Field Mode) with 300x300 pixel. For each pixel, a spectrum covering the range 465-930nm is provided. MuseWise is the data reduction framework that is used within the MUSE collaboration. It is built on the Astro-WISE system, which has been extended to support 3D spectroscopic data and integrates data reduction, provenance tracking, quality control and data analysis. The MUSE pipeline is very flexible and offers a variety of options and alternative data flows to fit to the different instrument modi and scientific requirements. MuseWISE hast provenance "built-in", i.e. it stores all relevant provenance information during the execution of the pipeline. Our implementation presents this provenance information conform to the upcoming standard. Activity configuration is modelled as Entities, to enable accessing the provenance of the configuration, and for W3C compatibility. The provenance data are primarily presented as a relational database which is conform to the IVOA Provenance model and close to the upcoming ProvTAP standard. It can be queried via SQL and ADQL queries. The database covers the full processing chain from the exposure to the science-ready product, including all necessary entity, activity, usage, and generation descriptions. On top of the relational representation, we developed a few tools for alternative access methods: 1. A complete ProvSAP server that translates REST queries into relational queries for a provenance database, converts the result into the W3C Provenance model and presents it in W3C formats (XML, Prov-N, OWL2, JSON). The part of the IVOA model that is not W3C compatible (ActivityConfiguration package) is not queried. The result can be processed and stored by any W3C compatible tool and service. 2. A tabular vizualisation prototype of the provenance based on the W3C model (from the first tool), to present the data to the user. This page shows an example output for the complete chain of one data product. We also tested this prototype on other available data that we locally stored in databases with the same structure as our MuseWISE implementation: HIPS generation, CTA, and cube segmentation.APPLAUSE Provenance: publically available implementation via TAP (A. Galkin)
German astronomical observatories own considerable collection of photographic plates. While these observations lead to significant discoveries in the past, they are also of interest for scientists today and in the future. In particular, for the study of long-term variability of many types of stars, these measurements are of immense scientific value. There are about 85000 plates in the archives of Hamburger Sternwarte, Dr. Karl Remeis-Sternwarte Bamberg, and Leibniz-Institut für Astrophysik Potsdam (AIP). The plates are digitized with high-resolution flatbed scanners. In addition, the corresponding plate envelopes and observation logbooks are digitized, and further metadata are entered into the database. The APPLAUSE implementaion of the provenance model is the only publically accessable imlementation and is accessible through the TAP protocol on https://www.plate-archive.org Currently, the provenance schema for the APPLAUSE Data Release 3 has 528082 entities, 425421 activities, 327 agents, 799097 used relations, 471888 wasGeneratedBy relations and 138552 wasAttributedTo relations.Implementations Validators
There is no validator for the model as such. Validation tools should be applied to specific implementations of the model.RFC Review Period: 2019 July 23 - 2019 September 03
Comments from WG members
Comment from -- LaurentMichel - 2019-08-26- suggest to put a special mention in the acknowwledgements for Kristin Riebe, as former editor, and another for Mark Cresitello Ditmar and Janet Evans who were so much involved in the project.
Comment from -- LaurentMichel - 2019-08-26 on behalf of Harry Enke <henke@aip.de>
- Intro,para2: (p1.)
"The provenance of scientific data is a part of the open publishing policy for science data and follows some of the FAIR principles for data sharing."
I suggest to substitute this sentence with:
"Provenance of scientific data is one components of the FAIR principles: "(4.3) Published data should refer to their sources with rich enough metatdata and provenance to enable proper citation". (Force11, FAIR Principles)
This provenance model goes beyond the FAIR principles, its intent is to make the generation of astronomical data accessible. "
=> This sentence is confusing and slightly misleading: there is no "open publishing policy", because policies require a body which gives this policy to itself and
implements some enforcement measures. And why not pointing to the direct reference in FAIR ? It's good we have some.
- "In astronomy, such entities are generally datasets composed of VOTables, FITS files, database tables or files containing values (spectra, light curves), any value, logs, documents, as well as physical objects such as instruments, detectors or photographic plates."
I suggest to clarify:
"In astronomy, such entities are generally datasets composed of VOTables, FITS files, database tables or files containing values (spectra, light curves), any value, logs, documents, as well as descriptions of physical objects such as instruments, detectors or photographic plates, or information about software."
=> (see paragraph above: 'information about...)
a) not the machinery itself, but the description can be included as provenance information
b) I think that software (even though it's not explicitly addressed) also could have provenance information
- "General Remarks:" (p8)
"Another important usage of provenance information is to assess the pertinence of a product for scientific objectives, which can be facilitated through the selection of the relevant provenance information attached to an entity that is delivered to a science user."
I suggest:
"Provenance information delivers additional information about the scientific data set to enable the scientist to evaluate its relevance for his work. "
=> This is hard to understand,if one substitutes "pertinence" with
"relevance" (because they are synonyms) you get a kind of tautology
(relevance of a product => select relevant provenance information)
- Best Practices: (p.9)
"The following additional points are recommended when managing provenance information within the VO context:"
should be
"The following additional points are recommended when providing provenance information within the VO context:"
=> since all following statements are clearly for providers of provenance infomation
- 13. Role ... (p. 10)
"The IVOA Provenance Data Model is structuring and adding metadata to
trace the original process followed during the data production for providing astronomical data. "
should read:
"The IVOA Provenance Data Model is structuring and adding metadata to
trace the processes of the data production for providing astronomical data."
=>It's neither reasonable nor required to restrict the provenance to 'original processes'.
Comments from Markus Demleitner
Revisiting the two reviews I've written on this before, let me say that despite the points below, this version of the document is much improved. Thank you for that. Some concerns remain, however. In the list below, I've marked some I consider show stoppers with (!). Everything else is somehwere on the spectrum between woulnd't-it-be-nice and mark-my-words. In my review of a previous version 2017-09, I made the point that the document has no guidance for how to replace the plethora of FITS keywords with a with a ProvDM-compatible representation. I still think having a section in the introduction or an Appendix on this would make the document much easier to digest to the wider community. And if you adopt VOTable types (please! please!), you can scratch current Appendix C, so the document wouldn't even get longer. In my review of the previous PR 2018-10, I wrote: "I'd strongly vote for having the core model put into REC frist and only then going for the extended model" on grounds that it's difficult enough to get the core right. While I'd still vote for this if it were an option -- in particular because once we have interoperable clients that consume this kind of thing, we're far less likely to waste a lot of work on things clients won't or can't look at --, I'll grudgingly shut up on this and trust that people have made sure there's no way to have a VO-useful model without the extended part. (1) Personally, I'm not a big fan of the List of Figures and the List of Tables. If you're not terribly attached of them, consider dropping them. One less page, 2% less scary spec. Response : Provenance is multi-faceted, and these tables help to retrieve components or feature descriptions. -- MathieuServillat - 2019-09-26 (2) ivoatex uses non-French spacing by default, which means that after a full stop there is additional white space. The result is that if you have a period character that is not a sentence end (e.g., "i.e." or "e.g."), you should do something. The preferable way is to have a comma after abbreviations like "i.e.", which is what style guides still tell you to have. Where no comma is appropriate, use a tilda (as in "M.~Demleitner"). Also typographically, there are a few naked double quotes (") left in the text, and it would be nice if they could be replaced by typographical quotes (e.g., Use Case C: "well", "unbounded" in Table 14). There's also a typo in 2.5.3: "GenerationDescription classes[,] that are meant to store" -- the comma doesn't belong there. Response : Ok, “e.g.” are followed by a comma, and “i.e.” by a tilde as recommended in English, and typographical quotes are used. -- MathieuServillat - 2019-09-26 (3) In use case (B), there's "Find out who was on shift for data taking for a given dataset", which differs in style from the other bullet points, which are questions. Why not write "Who was on shift while the data was taken?"? Response : Agreed and updated. -- MathieuServillat - 2019-09-26 (4) In use case (C) you write "Is the dataset produced or published by a person/organisation I can trust?" -- that's a bit marginal, and I'd prefer if it was withdrawn. If you take that use case seriously, you'll have to derive the requirement that the provenance itself becomes trustworthy, which then entails signatures and a public key infrastructure, which is something we certainly don't want to go into here. So, if you're not too attached to this particular thing, I'd prefer if it went away. Response : Provenance is about quality, reliability and trustworthiness and this use case corresponds to real situations for some astronomers. The way to establish the trust is not part of the standard, but it does not necessarily imply the use of signatures and a public key infrastructure, this can be achieved by a personal judgement based on some provenance information. The text has been changed to: "Is the dataset produced or published by a person/organisation I rely on? Using methods I trust?” -- MathieuServillat - 2019-10-08 (5) in use case (D), third bullet point, there's "coding language version", which I think at least lacks commas but would certainly profit from a tiny bit more verbosity. *Response*: Agreed, the text has been updated to: “What was the execution environment of the pipeline (operating system, system dependencies, software version, etc.)?” -- MathieuServillat - 2019-09-26 (6) in "General Remarks", you talk about it being "possible to enable the reproducibility", which opens a can of worms ("workflows") that I'd rather keep out of Provenance. Again, if you're not terribly attached to that passage, I'd rather see it removed. Response : Reproducibility is written as a requirement for some projects, and it is cited in the FAIR principles article, close to the R of Re-usable, where “provenance“ is also cited. For those reasons, reproducibility is cited in this document. However, it is not written as an objective, but as a possibility, so that the proposed data model does not by itself focus on reproducibility. Provenance is about what happened and workflows about what will happen. In this document we only consider the provenance point of view (otherwise, there would be other requirements for the model). -- MathieuServillat - 2019-10-08 (7) I'm a bit confused by the distinction between "Model requirements" and "Best practices", in particular because quite a few of the "best practices" are actually required if you want to cover your use cases. Why did you create these two classes? And what's the relationship of the "best practices" to the modelling? It seems to me that something like "an entity should be linked to the activity that generated it" could simply be written as an actual requirement like "The model must link entities with the activities that generated it". That would, at least to me, indicate that a constraint on the model is being derived. Response : “Model requirements” are for the model design and definitions. “Best practices” are intended for the usage of the model. The text for best practices has been updated to: “The following requirements concern the provenance usages in the VO context”. -- MathieuServillat - 2019-10-08 (8) In sect. 1.4, the transition from "...was slowing down." to "The IVOA Data Model Working Group first gathered various..." is a bit sudden. Perhaps something like "To regain momentum" or so would improve the narrative here? Response : Agreed and updated in the text. -- MathieuServillat - 2019-09-26 (9) For the record, I still think the model's implementability would greatly profit from dropping the loop relations (wasDerivedFrom and wasInformedBy) -- they induce a combinatorial explosion of possible vertices to inspect when following a provenance chain (in an 11-entity provenance chain, you have to look at 21 vertices without them, and about 1045 ones with them). To me, that's a bad deal for saving on possibly empty Activities (or Entities). But well, I guess I can only hope I won't have to deal with this. Oh, and I mention in passing that when drop the loop relations, you also get to drop WasAttributedTo. How good can a deal get? Response : This comment was already discussed previously, and it was decided to keep the relations, in their minimal form for now (no class or attributes). They are common relations found in our use cases, and there is also W3C compatibility. For example, a provider may just give the information that a dataset was derived from a progenitor. This concept is also already found in DataLink (progenitors and derivations). For a client or user of this information, it is thus needed to handle those concepts. However, they may be handled internally with the core classes if this seems easier to implement. -- MathieuServillat - 2019-10-11 (10) I haven't been able to work out what "optional" means in this specification, and I'd suggest explaining it somewhere in the introduction. Does it mean a client can ignore specifications in optional elements and still be compliant? If it means something else, what is it? And what about writers? Do writers have to write all "non-optional" elements? Response : The word “optional” is now removed from the document. We note that many relations and attributes in the model have cardinality [0..something], which means that they are optional (in the sense that an instance without those relations or attributes is valid). -- MathieuServillat - 2019-10-11 (11) In 2.5.1, you write "An activity is then a concrete case (instance) with a given start and stop time, and it refers to a description for further information." -- given that startTime, stopTime and description are optional as per Table 2, that is a misleading statement (and of course "description" is called "comment" in Activity). Can't you just write "ActivityDescription in this sense is a template defining the metadata of a set of slots filled using an AcitivityConfiguration to build a concrete Activity"? [disclaimer: I may not have quite gotten the plan straight on this first reading] Response : ActivityDescription is not exactly a template, but it structures descriptive information common to several activities, where an activity is something that occurs over a period of time (there exist a start and a stop time). The text has been simplified to: “The information necessary to describe how an activity works internally are stored in ActivityDescription objects.” It is also important to distinguish a description and a comment (see item 12 below). -- MathieuServillat - 2019-10-08 (12) If there is some systematics behind the apparent inconsistency that human-readable annotation is in the "description" attribute in ActivityDescription but in the "comment" attribute in Activity? If so, it would help adopters if it were explained. Response : The text in table 10 has been changed to: “description, additional free text describing how the activity works internally”. Annotation, in the sense “adding a note or comment to something”, is different from a description. A description is general and can be written before execution (in an ActivityDescription object), but a comment is added after, for a specific execution (maybe indicating why it was executed, in which context…). The model does not provide an annotation system, but a single comment at the creation of an activity. -- MathieuServillat - 2019-10-08 (13) I can't say I like "doculink" too much. Is there a strong reason not to use the term "reference URL" that's well established for what I take this to be? Response : This attribute is a “link to further documentation”, so not exactly a reference URL for the object. It is now changed to “docurl” that may be less quirky. -- MathieuServillat - 2019-10-08 (14) Table 13 and 14: There's multiplicity there, but it's not really clear what should be there if it were, say, "zero or one", or "exactly two", or really anything else than an unbounded number of entities. The text on p. 24 also suggests to write multiplicity=*, which isn't mentioned at all in the tables. (!) Response : The content of the multiplicity attributes is now clearly fixed and given with examples: “The multiplicity syntax is similar to that of VO-DML (VODML 1.0, 4.19) in the form “minOccurs..maxOccurs” or a single value if minOccurs and maxOccurs are identical, e.g., “1” for one item, “*” for unbounded or ”3..*” for unbounded with at least 3 items.” -- MathieuServillat - 2019-10-08 (15) On p. 24, there's the sentence "For example: when the input bias files..." that than peters off without saying what happens then. I can marginally see that with more effort a reader might be able to figure out the "then" part, but I guess it would be a nice service to say "the EntityDescription referencing the UsageDescription would declare..." (or whatever; I admit I've not tried very hard to figure it out myself). Response : Ok, the text has been updated: “For example: if the input bias files are expected to be in FITS format, the UsageDescription object would have a relation to a DatasetDescription object with contentType=application/fits.” -- MathieuServillat - 2019-09-26 (16) In table 18, I'm deeply unhappy to see that you're requesting a VO-DML type to describe the data type. In both Registry and DAL (TAP), we've regretted trying shortcuts from VOTable types -- most of the values we're talking about are (at least optionally) going to end up in VOTables, so generating code in all likelihood already knows about VOTable types. Nobody will have thought about VO-DML types. Also, the VOTable is rich and implies serialisation -- you really don't want to go into all the intricacies of timestamps and polygons and all that again. So, please, please use datatype, arraysize and xtype as in VOTable here. I notice in A1 that the move to VO-DML types apparently was a change made towards this PR. Why was it taken? [I guess this is a good example why it pays to have public discussions on post-WD changes]. Response : Ok, the content of the valueType attribute will be taken form VOTable datatype, thus replaced by 3 attributes: datatype, arraysize and xtype. This has been a concern for most of the authors, as using VODML types for data types would be somewhat new and untested. It was introduced in November 2018 to be more abstract and general on the values manipulated. However, the values manipulated here are generally data of primitive types, so it may indeed be a better match with VOTable datatypes. -- MathieuServillat - 2019-10-11 (17) In table 18, you say the possible values are "comma separated" -- but what happens if a value contains a comma? You might get by referencing the CSV standard that has escaping rules, but really: my advice is to just get rid of min, max, and options -- I don't see overwhelming use cases, and their semantics becomes really hard once you start digging (e.g., arrays: min, max of all components? by component? in some metric? cf. also the discussions on MAX interpretation in Geometries with SODA). (!) Response : Ok, the default/min/max/options attributes for ValueDescription are removed from the standard for now. However, they are also used in ParameterDescription where they have a more specific context (as part of an ActivityDescription). The multiplicity of options is changed to “*” so that it contains an array of string values. The serialization of this array may be defined later. -- MathieuServillat - 2019-10-11 (18) I can marginally see why you might want a ConfigFile class, though I'd much prefer if a configuration file were simply modeled as another input (i.e., Entity); I don't see what would be lost, and I can easily imagine quite a few cases when the line between a configuration file and something you would probably call an Entity is really blurred (e.g., a catalogue of sources). What I really object to, tough, is ConfigFileDescription -- this is nowhere near specified well enough to enable any sort of interoperable use. Also, the statement that ConfigFiles contain a "list of (key,value) pairs" is either meaningless (when you let value be just about anything and allow for arbitrarily complex keys) or too restrictive (when key is unique and value atomic). There's no way to write a client that will reliably understand any of this. In consequence, if a value should be available to a provenance reader, it needs to go into the provenance literally anyway. So, you don't lose anything you can do right now if you drop ConfigFileDescription, but you save pages and implementor confusion ("What the heck should I do with an ConfigFile that is application/x-votable+xml?"). If you absolutely have to have ConfigFile, then at least say it's opaque (and essentially just a special kind of entity), and drop the language on keys and values, as well as ConfigFileDescription. Side benefit: the uglyness of requiring name in ConfigFileDescription to match name in ConfigFile (which I take exception with, too) can go. Response : The text has been updated to: “The ConfigFile points to a structured, machine readable file, where parameters for running an activity are stored” and the mention of “key-value pairs” has been removed. It has been an important request for some use cases to make it possible to separate the configuration information and connect this information directly to the activity (i.e. it can be recovered with the activity identifier directly, as part of the activity). ConfigFile, being a storage for parameters, is thus part of the configuration package as is Parameter, and it is separated from the entities. The way configuration information can be handled is further presented in section 2.7. Given the structure of the model, the symmetry should be kept and ConfigFile comes with ConfigFileDescription (which is part of the ActivityDescription class). It indicates if an activity accepts or not a config file, which is a relevant description of how the activity works. -- MathieuServillat - 2019-10-11-- MarkusDemleitner - 2019-09-02
Comments from TCG Members
Early Comments from the Semantics WG
(1) The Provenance DM currently comes with the vocabulary http://www.ivoa.net/rdf/agent-role (though that is not stated in the spec as it is). This is nice and certainly the way to go, but the vocabulary itself is severely lacking at this point. My main concern is that the various terms are not really well specified, and some of them quite obviously overlap (creator vs. author, provider vs. publisher vs. curator). Since the vocabulary would become normative (meaning: no terms can be removed) when ProvDM becomes REC, this is bad enough that Semantics can't approve this as is. Ideally, there should be a use case for each term. Which essentially means: Only include terms people have actually used in their existing descriptions, and then extend the vocabulary as actual provenance descriptions require (this is going to be a reasonably easy and fast process; see http://docs.g-vo.org/vocinvo2.pdf for the current draft). If that's impossible for lack of existing descriptions, my initial list would be to have the terms:- creator -- a person who significantly contributed to the execution of an activity or the creation of an entity, such as an article's author, the operator of a pipeline that created the entity, or a researcher who selected and combined flatfields into a master flat.
- publisher -- a person or institution making an entity available. For entities available on the web, this would be the server operator.
- funder -- an institution who provided financial means for executing an activity or creating the entity.
- contact -- a person or institution that can respond to questions regarding an entity or an activity.
(2) I suspect that it would help a lot to have agreed-upon labels for roles as per 2.3.3 (e.g., letting a machine work out which inputs came from a the observation and which ones were (possibly common) calibration data. This would suggest using one or more vocabularies here. What if you suggested, for starters, to use terms from http://www.ivoa.net/rdf/datalink/core vocabulary (which have things like dark frame and such) if pertinent? This wouldn't keep people from using free text labels if that's not good enough, and later versions could add more vocabularies, but it would set clients on a right track as to using these roles. *Response*: Roles in Entity-Activity relations (2.3.3) appeared to be project specific and this REC does not provide a vocabulary for such roles. There is however, a list of terms proposed for the type of relation in Usage/GenerationDescription (Table 15), with some types identified in use cases (Main, Calibration...). Though some terms are also found in DataLink/core, the purpose is not here to link data, but to categorize a usage or a generation by an activity to better describe the provenance . -- MathieuServillat - 2019-11-22
(3) ActivityDescription/@type looks like another good candidate for offloading into a vocabulary. Let me know and I'll translate Table 11 to one (where I wonder whether Reduction, Calibration, and Reconstruction should be child terms of Analysis). One side benefit might be that you can do without ActivityDescription/subtype because the vocabulary gives you a hierarchy for free. And then you can have a controlled vocabulary there, as well, without having another free-text field. *Response*: The type attribute in ActivityDescription indicates a general category for an activity. From the use cases, there is a list of terms that emerged, mainly from the sequence of independent stages from data acquisition to data products, as commonly found in the astronomy domain. The subtype is project specific, and this REC does not provide a vocabulary for the subtype . -- MathieuServillat - 2019-11-22
(4) XDescription/@type seems like yet another case where using a vocabulary (i.e., basically translating Table 15) would help the general level of interoperability. Just browsing the terms, however, I'd say you should again be using (and extending as necessary) datalink/core here. The overlap between the lists of terms is rather compelling, and having two different term lists so close to each other would quite certainly confuse our users. Full disclosure: I also believe Datalink would profit if maintenance efforts on Provenance were to improve datalink/core. *Response*: Though there is some overlap between the lists of terms in Table 15 and DataLink/core, the purpose is different as answered above in (2) . -- MathieuServillat - 2019-11-22 -- MarkusDemleitner (with input from Carlo Maria Zwölf) - 2019-09-02
Comments from TCG member during the RFC/TCG Review Period: 2019-11-27 - 2019-12-13
WG chairs or vice chairs must read the Document, provide comments if any (including on topics not directly linked to the Group matters) or indicate that they have no comment. IG chairs or vice chairs are also encouraged to do the same, althought their inputs are not compulsory.TCG Chair & Vice Chair (Patrick Dowler, Janet Evans)
I downloaded and validated the VO-DML file (using https://github.com/opencadc/core/tree/master/cadc-vodml) and find that it is fully complaint with the VO-DML schema and schematron specs. This is expected but now no one else has to check that particular bit. Approved. -- PatrickDowler - 2020-04-06Applications Working Group (Tom Donaldson Raffaele D'Absrusco)
I have a variety of questions, espcially regarding serializations and how well they will be compatible with the more general W3C serializations. I also wonder about some of the more hypothetical details of how this might be used in practice. I think the only way to answer them is through more concrete implementations of both creating provenance instances for more datasets and having real users and tools consume that data. I expect these implementations would prove large parts of the standard sufficient, and would evolve the standard as needed. For this particular standard, I think the best way to encourage these new implementations is to approve this RFC. It seems well thought out, and is demonstrably well-enough specified to apply to concrete implementations. The level of demand for provenance data will likely drive the pace at which these new implementations are done, but there would at least be no reason to hold off on implementations due to the lack of a standard. I approve this RFC. -- TomDonaldson - 2020-01-28Data Access Layer Working Group (Marco Molinaro, James Dempsey)
The documents looks well written, minor typos and a few (minor) suggested changes will be delivered to the authors. We agree on the 'Semantics' concerns about the (semi-)vocabulary solution but won't veto the REC on this basis. We're a bit uncomfortable about the 'utype' naming choice while using VO-DML throughout, but that's again not blocking. We thus approve this specification and look forward, from the DAL perspective on its usage in protocols for accessing/analysing data holdings. -- MarcoMolinaro, JamesDempsey - 2020-02-10Data Model Working Group (Laurent Michel Jesus Salgado)
All of the comments and suggestions of the DM (co)chairs have been proposed during the different steps of the standard elaboration. Thus DM approves.Grid & Web Services Working Group (Giuliano Taffoni, Christine Banek)
Registry Working Group (Theresa Dower, Pierre Le Sidaner)
I am in agreement with the Semantics chair that moving the scattered terms to standard vocabularies would be beneficial, and at this point easiest to do as a post-1.0 change. Also agreed that the "list of terms could be updated..." text does not need to be in the document itself; recording the intention here in RFC and simply making the change in any future version of the Provenance document is cleaner. I note that there are vocabulary items like publisher in agent roles which have meaningful information associated with them in the IVOA registries. Adding an optional element (more accurately attribute, at least in the xml serialization) for that reference where appropriate could be useful. It would also introduce an externality to the data model for better and for worse, so I'm happy noting it as a potential future item along with the general vocabulary externalizing noted above, and not adding any such references at this time. -- TheresaDower - 2020-02-03Semantics Working Group (Markus Demleitner, Carlo Maria Zwölf)
Semantics certainly is not thrilled by the loose term lists scattered around the document (as mentioned in our preliminary comments above). In particular, we caution that the sheer number of ill-defined terms in agent-roles will make that field essentially useless for interoperable clients because it will be unclear what to look for for which purpose. We also would prefer if the language "This list of terms could be updated to follow the IVOA vocabularies 2.0 recommendation once adopted." (caption on tables 9, 11, 15) were removed – it does not help at all since it doesn't say under which circumstances the "could" would become a "will" and what that "update" would mean in practice, and if there's something producers or consumers of provenance could do to prepare for it. Indeed, it would be hard to say anything of that sort: once you have all the wild and overlapping terms in the fields, the way back is thorny: either you introduce a precise vocabulary and invalidate existing documents in (ok: IMHO tolerable) violation of IVOA policies, or you issue a new major version of provenance, or you start with a vocabulary full of deprecated terms – all of which do not seem terribly desirable. So, saying nothing on this is better than language that is more confusing than helpful. While we still feel that the standard's usefulness would be helped if it adopted minimal vocabularies using what's in use for Datalink, VOResource, and VOTable already instead of the current informal word lists, we won't stand in the way of adoption if all other WGs think the standard should go ahead. -- MarkusDemleitner - 2019-12-02Data Curation & Preservation Interest Group (Andre Schaaff, Tim Jenness)
Education Interest Group (Chenzhou Cui, Hendrik Heinl)
Knowledge Discovery Interest Group (Kai Lars Polsterer, Matthew Graham)
Solar System Interest Group (Baptiste Cecconi, Steve Joy)
Theory Interest Group (Carlos Rodrigo, Gerard Lemson)
Time Domain Interest Group (Ada Nebot, Dave Morris)
Operations (Mark Taylor, Steve Groom)
Provenance and Data Models are far from my expertise, and I haven't given any thought to implementations based on this model. But the document seems clear and well-drafted, and I don't forsee any Operational issues arising from its adoption. Ops recommends acceptance. -- MarkTaylor - 2019-11-29Standards and Processes Committee (Christophe Arviset)
TCG Vote : 2019-11-27 - 2019-12-13
If you have minor comments (typos) on the last version of the document please indicate it in the Comments column of the table and post them in the TCG comments section above with the date.
| Group | Yes | No | Abstain | Comments |
| TCG | * | |||
| Apps | * | |||
| DAL | * | |||
| DM | * | |||
| GWS | * | |||
| Registry | * | |||
| Semantics | * | |||
| DCP | ||||
| KDIG | ||||
| SSIG | ||||
| Theory | ||||
| TD | ||||
| Ops | * | |||
| StdProc |


| I | Attachment | History | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|---|
| |
ImageProvHiPS.jpg | r2 r1 | manage | 92.2 K | 2019-08-20 - 14:19 | FrancoisBonnarel | HST HiPS and tiles provenance metadata |
| |
OntologyProvenance2019-07-22.png | r1 | manage | 124.6 K | 2019-07-22 - 20:07 | MireilleLouys | list of owl objects in the Prov-test ontology M.Louys |
| |
OwlOntologyPanel1.png | r1 | manage | 297.9 K | 2019-07-24 - 16:22 | MireilleLouys | list of owl objects, properties and predicates in the Prov-test ontology M.Louys |
| |
P2-6.pdf | r1 | manage | 608.8 K | 2020-11-10 - 16:56 | MireilleLouys | adass 19 poster paper: Implementation feedback of the IVOA Provenance data model |
| |
ProvQuerytest-3store.pdf | r1 | manage | 45.1 K | 2019-07-22 - 19:57 | MireilleLouys | List of example queries for CDS Triplestore implementation. M.Louys |
| |
VisuProvenance.png | r1 | manage | 443.8 K | 2019-08-20 - 14:41 | FrancoisBonnarel | full provenance chain HiPS HST 1 |
| |
VisuProvenance1.png | r1 | manage | 622.9 K | 2019-08-20 - 14:41 | FrancoisBonnarel | full provenance chain HiPS HST 2 |
| |
VisuProvenance2.png | r1 | manage | 560.9 K | 2019-08-20 - 14:42 | FrancoisBonnarel | full provenance chain HiPS HST 3 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Topic revision: r43 - 2020-11-10 - MireilleLouys
Log in or Register
IVOA.net
Wiki Home
WebChanges
WebTopicList
WebStatistics Twiki Meta & Help
IVOA
Know
Main
Sandbox
TWiki
TWiki intro
TWiki tutorial
User registration
Notify me Working Groups Interest Groups Committees
www.ivoa.net
Documents
Events
Members
XML Schema
Wiki Home
WebChanges
WebTopicList
WebStatistics Twiki Meta & Help
IVOA
Know
Main
Sandbox
TWiki
TWiki intro
TWiki tutorial
User registration
Notify me Working Groups Interest Groups Committees
www.ivoa.net
Documents
Events
Members
XML Schema
 |
|
Ideas, requests, problems regarding TWiki? Send feedback